Non classé
Navigating the Energy Demands of AI: How Data Center Growth Is Transforming Utility Planning and Power Infrastructure
Published
9 mois agoon
By
Powering data centers is a challenge for utilities.
Data centers are highly valued by utilities because they consume large amounts of electricity with consistent, predictable demand patterns that remain steady throughout both the day and the year.
The explosive growth in power demand, driven largely by Artificial Intelligence (AI) and cloud computing, has overwhelmed the traditional electrical grid planning and construction timelines.
Introduction
New hyperscale data centers often require 100 MW to 500 MW of power, which is the demand of a small to medium-sized city. Utilities are happy to accept new business, but the problem is that data center developers want this power now and utilities are not prepared to respond so quickly. Expanding transmission and substation capacity through utilities can take 5 to 10 years due to lengthy processes for planning, permitting, environmental reviews, and construction. Data center developers, especially those focused on the AI race, prioritize “time to power” above almost all else. Delays mean lost competitive advantage and revenue. Developers are willing to pay a premium for faster power access and have taken some new and unique approaches for powering data centers.
The need for gigawatts of power on tight deadlines has forced data center developers to become major energy developers. They are doing this in three main ways:
Funding Renewables via PPAs: Hyperscalers like Amazon, Microsoft, and Google are the world’s largest corporate buyers of clean energy. Their long-term Power Purchase Agreements (PPAs) provide the financial certainty needed for developers to build hundreds of new utility-scale wind and solar farms.
On-Site, Grid-Independent Power: To bypass multi-year grid connection queues, developers are building their own on-site power. They have purchased natural gas turbines, fuel cells, and co-located them next to renewable power, independently of the local utility.
Direct Connections to Power Plants: Data center campuses are now being planned and built adjacent to existing power plants. There are several major data center developers like Microsoft, Google, Meta, and Amazon web services that have signed PPA’s for existing nuclear power, like the Microsoft deal for a 20-year PPA to enable the restart of the shuttered Three Mile Island reactor in Pennsylvania. There is interest and research into PPA’s for new SMR, advanced, and full-scale nuclear power
Example of the new paradigm
The massive xAI “Colossus” data center project in Memphis, Tennessee, showcases a new paradigm for building AI infrastructure at incredible speed. To rapidly meet the massive power demands of the Colossus data center, xAI used portable or mobile natural gas-powered turbines which are typically used for disaster recovery or fast, temporary power generation. This resulted in legal challenges from environmental groups regarding air quality permits and were eventually removed.
Initial reports mentioned around 18-20 turbines, but later aerial images suggested as many as 35 turbines were installed and operating, with a combined capacity estimated at over 70 MW, though the total demand for Phase I was 150 MW. The TVA (Tennessee Valley Authority) Board of Directors officially approved the plan to supply a total of 150 MW of power to the xAI facility in November 2024.
The connection to the full 150 MW load required the construction of a new electric substation near the data center, which was paid for by xAI. By May 2025, the massive Colossus supercomputer facility was connected to the new substation, providing it with 150 MW of power from the MLGW/TVA grid.
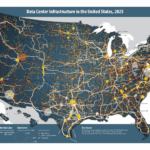
The map shows where new data centers are being built.
Data Centers planned in the US
While many data center plans are secrets, current expansion announcements focus on regions like:
Northern Virginia (Ashburn/Loudoun & Prince William Counties): The largest existing and planned capacity globally.
Phoenix, Arizona (Maricopa County): A major emerging market with high growth projected.
Dallas-Fort Worth (DFW), Texas: Significant planned growth.
Atlanta, Georgia (I-85 Corridor): High percentage growth projected, with major new investments.
Salt Lake City, Utah: A fast-growing secondary market.
Impact on utilities and power costs.
There is fierce competition to build and power data centers unlike anything we have seen in the utility industry before, but there is also significant new power growth due to the growing power demands for electric powered transportation (mostly electric passenger cars) and to a lesser extent the electrification of HVAC and industrial electrification. The increased demand for power requires new utility investment in transmission, substations, and distribution.
The generation side is split between vertically integrated regulated utilities and Independent Power Producers (IPPs). Independent Power Producers (IPPs) have generally dominated the buildout of new capacity (especially renewables and battery storage), particularly in deregulated markets, because they can respond to market price signals and secure private long-term contracts (PPAs) faster than utilities navigating regulatory approval cycles.
Utilities remain the primary developers in the regulated markets and are also heavily investing in transmission and distribution infrastructure across all markets to physically connect the new generation built by both themselves and IPPs.
With data centers buying and building power there is a supply and demand issue that is driving up the cost of power. A small utility or municipal power company without generation buys power from IPP’s or other utilities suppliers and is competing with the data centers.
Utilities see data centers as great customers. They buy lots of power with steady daily and seasonal loads. They match up well to base load generators like nuclear or coal power and do not require oversized transformers or wires like a large level 3 EV charging facility would need. Of course, data center developers are concerned about power costs and new data centers have many ways they can be better customers and get better power rates from utilities. About 40% of the data center power goes to HVAC. There are ways of using thermal batteries to shift the HVAC load away from costly peak power hours typically 5-9pm There is a trend for data centers to transition to large grid scale batteries that are replacing the traditional UPS batteries. Such batteries can provide useful grid services to utilities as well as provide backup power to the data center. A town or utility that adds data centers to their grid will gain revenue for power sold. More revenue helps to cover the large overhead costs that utilities have for wires, poles, truck, staff, and buildings. This can reduce the overall cost of power in such towns or utility service areas
The Leading AI Model Developers
1. OpenAI (in partnership with Microsoft). Flagship Products: The GPT series ChatGPT Microsoft is their primary investor and exclusive cloud partner, integrating OpenAI’s models deeply into their own products like the Azure cloud platform and Microsoft Copilot.
2. Google (specifically Google DeepMind) Flagship Product: The Gemini family of models (including Gemini Pro, Ultra, and future versions).
3. Meta (formerly Facebook). Flagship Product: The Llama series of models (e.g., Llama 3).
4. Anthropic Flagship Product: The Claude family of models (e.g., Claude 3, Claude 3.5 Sonnet). They are a major competitor to both OpenAI and Google and are heavily backed by Amazon and Google.
5. xAI Flagship Product: Grok. Founded by Elon Musk, xAI aims to create an AI to “understand the true nature of the universe.”
6. DeepSeek AI. Flagship Product: The DeepSeek model family (e.g., DeepSeek-V2). They are a leading Chinese AI research lab that has released a series of extremely powerful open-source models that are highly regarded, particularly for their exceptional coding and mathematical reasoning capabilities.
Is there an investment bubble like the dot com bubble?
The short answer yes, the massive overspending by companies like Meta will shift from being first at all costs to a more rational return on investment criterion. However, the race is not stopping, and it is unlikely to see the AI race coming to a halt. Current spending projections are:
2025: ~$400 Billion The spending in 2025 is dominated by the massive capital investment in building the physical infrastructure for AI. Data center construction and the procurement of tens of billions of dollars’ worth of NVIDIA GPUs and other AI accelerators represent the largest share of this cost.
2026: ~$550 Billion The rapid year-over-year growth is driven by the ongoing AI arms race. As new, more powerful AI models are released, the demand for even larger data centers and next-generation GPUs continues to accelerate. Spending on the electrical infrastructure to power these facilities becomes a major and growing line item.
2030: Over $1.5 Trillion The leap to a multi-trillion-dollar run rate by 2030 is based on the widespread enterprise adoption of AI. By this time, spending will shift from being concentrated among a few hyperscaler’s to being broadly distributed as thousands of companies build their own smaller AI systems and pay for massive amounts of AI-powered cloud services.
Electric Power: This is the fastest-growing operational cost. Powering the millions of GPUs in these data centers is projected to become a multi-hundred-billion-dollar annual expense by the end of the decade, making energy the primary long-term bottleneck for AI growth.
The race to develop the best AI applications that will provide your news, your library, your entertainment, your education, and maybe even your companionship. The AI investment race is showing early signs of potential market saturation and risk, but it is unlikely to subside completely due to fundamental differences from the dot-com bubble. Instead, most analysts predict a shift toward consolidation, disciplined spending, and a focus on profitability. The shake out could result in a small group of winners emerging, but the money for better AI models and new applications will keep flowing. This “AI Oligopoly” may be the current hyperscalers: Microsoft/OpenAI, Google, Amazon (with Anthropic), and Meta. The prize is not primarily scientific or industrial AI. It is about owning influence: I.e. the source of truth, knowledge, advertising, guiding your purchases, owning your news, owning your screen time, being your trusted teacher, partner, and friend. Having the best AI frontier model and model user interfaces is the key to success.
Factor
AI Investment Race
Outlook
Pace of Investment
Driven by an “AI arms race” where companies fear losing more than they fear overspending. This urgency is causing massive, debt-fueled spending on chips and data centers.
Likely to Slow/Correct. Infrastructure spending cannot increase indefinitely. Goldman Sachs and others predict an “inevitable slowdown” in data center construction, which will impact chip and power suppliers.
Productivity Gap
A significant gap exists between the trillions being invested in AI infrastructure and the proven, monetized revenue from AI applications.
Consolidation is Coming. Many smaller, unprofitable AI application startups are likely to fail or be acquired, similar to the dot-com era, as capital becomes more disciplined.
Technological Potential
The underlying technology (AGI/generative AI) is widely seen as genuinely transformational (a technological revolution).
Unlikely to Subside. The technology will not fail; the business models and valuations built upon it are the primary risk. Investment will pivot from “build it all now” to “build what is profitable.”
Conclusion and Outlook
The unprecedented demand in the US for lightning-fast power connections by developers of data centers is not matching traditional ways utilities provide power to new customers. As a result, there are a range of new and creative ways to provide that power. Developers are building their own power generation and microgrids. Data centers are becoming power companies themselves. They are building large BESS battery systems that not only provide for UPS power backup but provide grid services to utilities. Utilities and data center developers are collaborating on building new power generation, new or upgraded substations, and the power lines to meet the power and reliability requirements of data centers.
Data centers are a prized customer for utilities, they consume lots of steady power around the clock and throughout the seasons and they often have far more flexibility to provide ancillary services to the utility than typical residential, commercial or industrial customers. While they are schedule driven, they are less sensitive to the price of power in the short term as the AI race has focused on securing power faster than competitors to get the best AI models sooner and lock in a customer base with superior AI applications.
Hyperscalers have created shorter term PPAs for fossil power and long term PPA’s for massive quantities of renewable power and have memorandums of understanding for future nuclear power that may come from new SMR and advanced reactors. While data center loads match up well to base load generation like nuclear or coal, they are often powered by intermittent generation like solar and wind with battery storage.
Data center developers seek out locations that can provide power quickly, have the water and land resources needed and where local zoning and community are favorable. They are also building where it will be easy to expand in the future.
EV batteries are trending to charge at faster rates. Large high voltage DC EV charging stations can require massive power to charge dozens of cars simultaneously and utilities need a strong grid to service this growing load. Most EV charging occurs at home and distribution utilities are adapting to new loads with more powerful transformers and related low and medium voltage distribution infrastructure. New loads for HVAC and industrial electrification are steadily increasing over the next decade and beyond.
AI developers need more than just electric power to win the AI race. They need to train on accurate but diverse curated data. This includes selecting the most appropriate model architecture and employing techniques like Active Learning (to find the most useful data to train on) and Data Distillation (to reduce the size of the dataset without losing quality). They start with peta-bytes of data from public, private, and internally generated sources. This massive raw data pool is labeled, filtered, cleaned, and tokenized (broken down into the pieces the model understands). This step dramatically reduces the final size of the data AI uses for training. Data centers also need secure, reliable, and fast data connectivity.
The US is behind in securing new power. China already has a grid that is larger than the US and European grids combined and while NVIDIA GPU chips are restricted, China is in a far better position to provide power to AI Data centers compared to the US. The table below shows estimated grid power additions to 2030, and China is outpacing the US in every power sector.
Grid Energy
Global Additions in 2024 (GW)
US Additions 2025 to 2030
i.e., five years (GW)
China Additions 2025 to 2030
i.e., five years (GW)
Global Additions 2025 to 2030
i.e., five years (GW)
Solar
452
220 to 270
1,200 to 1,500
3000 to 4000
Wind
113
60 to 75
400 to 500
600 to 700
Coal
44.1
-50 to -70
120 to 180
160 to 240
Gas and Oil
25.5
25 to 35 GW
70 to 100
190 to 260
Hydro
24.6
2 to 4
60 to 80
125 to 175
Nuclear
6.8
~2 GW (uprating only)
30 to 40
50 to 70
Biofuel
4.6
1 to 2
8 to 10
30 to 40
Geothermal
0.4
2 to 3
2 to 3
10 to 15
Recent US policies are discouraging solar, wind, and battery storage, which is slowing the deployment of the cheapest, cleanest, and fastest deploying sources of new power. US policy is supporting more gas and nuclear power, but new gas power plants have supply chain constraints like gas turbines, so these power sources are not matching the demands of data center developers. This constrained power supply threatens to inflate electricity prices for consumers and businesses and risks leaving the nation unable to cleanly and affordably meet the surging power demands of data centers and broader electrification.
The post Navigating the Energy Demands of AI: How Data Center Growth Is Transforming Utility Planning and Power Infrastructure appeared first on Logistics Viewpoints.
You may like
Non classé
How Supply Chain Technology Providers Can Build Market Visibility with Research, Webinars, Podcasts, and Thought Leadership
Published
1 jour agoon
26 juin 2026By

Supply chain technology markets are crowded, complex, and changing quickly. Buyers are trying to separate durable capabilities from short-term claims, while solution providers are trying to explain where they fit in a market shaped by automation, AI, labor constraints, global disruption, network complexity, and rising expectations for operational performance.
In that environment, visibility alone is not enough. Providers need credibility, context, and market education. They need ways to reach the right audience with substance, not just promotion.
For many supply chain, logistics, transportation, warehouse automation, planning, visibility, global trade, and decision-intelligence providers, the challenge is not simply getting in front of the market. The challenge is helping the market understand why a capability matters, how it fits into broader operating realities, and what buyers should consider as they evaluate options.
That is where Logistics Viewpoints and ARC Advisory Group can help. Through market research, advisory services, sponsored thought leadership, webinars, podcasts, supplier spotlights, and industry event sponsorships, companies can engage the supply chain market in a more substantive way.
This article introduces a series on how supply chain technology providers can build credibility, visibility, and executive engagement through research, advisory services, sponsored thought leadership, webinars, podcasts, supplier spotlights, and industry sponsorships.
Over the next several posts, this series will look at each path in more detail, including when it is most appropriate, how it supports market education, and how companies can use it to strengthen positioning, credibility, and demand generation.
Market Visibility Has Changed
There was a time when visibility could be built largely through advertising, trade shows, press releases, and sales outreach. Those tools still have a role, but they are no longer sufficient by themselves.
Supply chain executives are operating in a more complex environment. They are evaluating technology in the context of labor availability, network volatility, service expectations, inventory policy, automation strategy, AI adoption, sustainability goals, regulatory change, and global risk. A narrow product message can easily get lost if it is not connected to the larger market conversation.
That is why market education matters. Buyers need help understanding what is changing, why it matters, and how different approaches should be evaluated. Providers that can contribute to that education are better positioned to build trust.
Research Helps Clarify the Market
Research is often the starting point for stronger positioning. A custom market research study can help a company answer specific strategic questions, test assumptions, evaluate market demand, understand buyer priorities, or explore a new category.
Standard market research can provide a broader foundation. It can help companies understand market size, technology adoption, competitive structure, and investment trends. For companies operating in complex supply chain technology categories, research can support product planning, executive alignment, sales enablement, and market messaging.
Annual advisory support adds another layer. It gives companies recurring access to analyst perspective throughout the year, helping them interpret market signals, refine positioning, and stay aligned with industry direction.
Thought Leadership Builds Credibility
Market credibility is not built through claims alone. It is built through perspective. Companies need to show that they understand the problems their buyers face, the tradeoffs involved, and the direction of the market.
Logistics Viewpoints sponsorship, webinars, podcasts, and supplier spotlights can all support this goal in different ways. Sponsorship provides sustained visibility in front of an engaged supply chain audience. Webinars allow companies to explain complex issues in depth. Podcasts create room for executive perspective and market narrative. Supplier Spotlights help clarify company positioning through an analyst-framed discussion of strategy, capabilities, and differentiation.
The strongest thought leadership does not begin with a product pitch. It begins with a market problem. It helps the audience understand the issue, evaluate possible responses, and connect the discussion to broader operational priorities.
Events Create Strategic Market Presence
Some conversations are best developed through direct industry engagement. Events bring together executives, practitioners, analysts, technology providers, and decision-makers around the issues shaping the future of operations.
ARC Industry Forum sponsorship gives companies an opportunity to connect their brand and message with a broader executive audience. For organizations focused on supply chain, logistics, manufacturing, automation, industrial technology, infrastructure, and enterprise transformation, this can be a way to participate in the strategic conversations that influence market direction.
Choosing the Right Path
The right program depends on the business objective. A company looking to answer a specific strategic question may begin with custom research. A team that needs recurring market perspective may benefit from annual advisory support. A provider seeking broader awareness may look at Logistics Viewpoints sponsorship. A company with an educational story may choose a webinar. An executive team with a strong market point of view may choose a podcast. A supplier that needs clearer positioning may pursue a Supplier Spotlight. A company looking for strategic industry presence may consider ARC Industry Forum sponsorship.
These programs are not mutually exclusive. In many cases, the strongest market engagement strategy combines research, advisory insight, thought leadership, and audience activation. Research can clarify the market. Advisory can sharpen the strategy. Webinars and podcasts can educate the audience. Sponsorship can sustain visibility. Supplier Spotlights can reinforce positioning. Industry events can deepen executive engagement.
The common thread is credibility. In a noisy market, buyers respond to clarity, relevance, and substance. Companies that can explain where the market is going, why it matters, and how they help customers respond will be better positioned to earn attention and trust.
For supply chain technology and logistics providers, the opportunity is not just to be seen. It is to be understood.
Explore the Series Resources
For companies evaluating the best way to build market visibility, the following program overviews provide more detail:
Custom Market Research Study
Annual Contract Advisory Service
Standard Market Research Report
Logistics Viewpoints Sponsorship Program
Sponsored Webinar Program
Sponsored Podcast Program
Supplier Spotlight Program
ARC Industry Forum Sponsorship
If you have questions about which type of program fits your company’s market objectives, reach out to me directly at jfrazer@arcweb.com. I’d be glad to discuss where your priorities align with the Logistics Viewpoints and ARC Advisory Group editorial, research, and market engagement calendar.
The post How Supply Chain Technology Providers Can Build Market Visibility with Research, Webinars, Podcasts, and Thought Leadership appeared first on Logistics Viewpoints.
Non classé
Supply Chain and Logistics News Weekly Round Up June 22nd-26th 2026
Published
1 jour agoon
26 juin 2026By

The global supply chain landscape is currently defined by rapid transformation and persistent volatility. This week’s developments underscore a shift toward greater operational resilience and adaptation, ranging from the immediate impact of the CBP’s suspension of the de minimis exemption to the mounting pressure of early peak season rate spikes. As shippers navigate these headwinds, we are also seeing structural long-term pivots, including significant federal investments in domestic nuclear manufacturing and a fundamental rethink of Transportation Management Systems—moving away from traditional software toward integrated, outcome-driven operating models. This week’s round-up explores how these forces are reshaping procurement, execution, and strategy for logistics professionals.
The End of De Minimis: CBP Suspends Low-Value Duty-Free Imports
In a monumental shift for cross-border e-commerce, U.S. Customs and Border Protection (CBP) has implemented an interim final rule that indefinitely suspends the de minimis administrative exemption, which previously allowed shipments valued at $800 or less to enter the country duty-free with minimal clearance. As detailed in the Federal Register Interim Final Rule, all commercial imports arriving via ocean, air, and trucking lanes must now undergo formal or informal customs entry procedures, exposing them to standard tariffs and rigorous compliance checks. The sudden change, also highlighted in the official U.S. Customs and Border Protection Press Release, temporarily spares only the international postal network under a strict, flat-rate tariff structure. For direct-to-consumer (DTC) brands that have built entire supply chains around direct-from-factory shipping, this regulation effectively erases their primary cost advantage overnight. Logistics planners must now scramble to transition from fragmented individual parcel shipping to bulk ocean freight, bonded warehousing, and localized domestic distribution strategies to absorb the sudden surge in operational costs and clearance times.
Ocean Freight Spot Rates Surge as Early Peak Season Collides with Port Congestion
Global container freight markets are experiencing severe pricing pressure as an exceptionally early peak season collides with systemic network constraints. According to the latest Locada Intelligence Report, spot rates from Asia to the U.S. West Coast have jumped by over 23% to cross $6,800 per FEU, while East Coast routes have surged past the $8,100 threshold. This dramatic spike is being driven by sustained shipping diversions away from the Red Sea, acute port congestion, and a preemptive rush by retailers to front-load holiday inventory. With major carriers signaling further general rate increases that could push spot rates toward $10,000 per FEU on key lanes, shippers are urged to diversify their transport modes, secure capacity early, and prepare for a highly volatile and expensive third quarter.
Shoring Up the Grid: DOE Injects $17.5 Billion to Rebuild the Domestic Nuclear Supply Chain
To safeguard the nation’s energy independence and accelerate clean grid transitions, the U.S. Department of Energy (DOE) has announced a massive $17.5 billion loan initiative aimed at financing the manufacturing of nuclear reactor components. As reported by Mining.com Coverage, the funding targets critical vulnerabilities in the specialized, highly concentrated upstream supply chain, which has historically plagued large-scale energy projects with severe delays. By providing low-cost capital to domestic fabricators of heavy forgings, coolant pumps, and control systems, the initiative seeks to establish a resilient, highly localized manufacturing base. For supply chain managers within the industrial and utility sectors, this federal backing—signified by Westinghouse’s secured allocations outlined in the Cravath Legal Announcement—signals a major push to de-risk high-consequence procurement, shifting reliance away from bottlenecked foreign suppliers.
Beyond Software: Why the Future of TMS is an Operating Model
The traditional software model for Transportation Management Systems (TMS), in which shippers purchase a system of record solely to execute tenders, routing guides, and audits internally, is rapidly shifting. Shippers are increasingly looking beyond basic software features to invest in entire transportation operating models. This evolution reflects a growing operational reality: deploying complex software does not automatically generate logistics excellence, particularly when an organization lacks internal process maturity, a robust carrier strategy, or real-time exception-management capacity. To bridge this execution gap, industry categories are blurring as TMS software, managed transportation services, and digital freight brokerages converge. Modern buyers are shifting focus away from legacy functional checklists and toward integrated solutions that bundle technology with embedded capacity, workflow automation, and concrete outcome ownership.
Autonomous Tendering Is Coming for the Routing Guide
The traditional, static routing guide, long the central control mechanism for freight execution, is struggling to keep pace with highly volatile transportation markets. In response, modern logistics operations are transitioning toward autonomous tendering, redefining the routing guide from a fixed ladder of preferred carriers into a dynamic, policy-driven decision framework. Instead of manually cycling through a sequence of static, pre-negotiated carrier rankings that may be outdated or misaligned with current lane conditions, next-generation systems continuously evaluate live variables. By analyzing real-time capacity, historical acceptance rates, spot market alternatives, service risk, and facility constraints, these platforms can determine which carrier is most likely to deliver the optimal outcome under current conditions. This evolution does not eliminate contract rates or human oversight; rather, it establishes automated guardrails that operationalize procurement expertise at scale, ensuring logistics decisions are optimized for real-world execution rather than historical assumptions.
The post Supply Chain and Logistics News Weekly Round Up June 22nd-26th 2026 appeared first on Logistics Viewpoints.
Non classé
Carbon Is Becoming a Routing Constraint, Not Just a Reporting Metric
Published
1 jour agoon
26 juin 2026By
For many transportation organizations, sustainability reporting has historically been a retrospective exercise. Freight moved through the network, emissions were calculated after the fact, and the results were used for corporate reporting, customer disclosure, or ESG documentation.
That model is changing.
Transportation emissions are beginning to move from the reporting layer into the decision layer. As shippers face growing pressure from customers, regulators, investors, and internal sustainability commitments, carbon data will increasingly influence mode selection, routing, carrier choice, consolidation, and service tradeoffs.
Download the TMS Market Research Executive Summary for a strategic view of how transportation management systems are evolving to support cost, service, and sustainability decisions.
The important shift is this: carbon is becoming a transportation constraint, not just a reporting metric.
From After-the-Fact Measurement to Operational Decision-Making
Most transportation emissions programs began with measurement. Companies needed to estimate the carbon impact of freight activity across modes, lanes, carriers, and regions. That required better data on shipment distance, weight, equipment type, fuel usage, mode, and carrier activity.
Measurement was a necessary first step. But measurement alone does not change operations.
The next phase is embedding emissions data into transportation planning and execution. A TMS that calculates emissions after the shipment is complete provides reporting value. A TMS that uses emissions during planning provides decision value.
That difference matters.
If a transportation planner can compare cost, service, capacity, and carbon before selecting a routing option, sustainability becomes operational. It becomes part of the same tradeoff structure that already governs freight decisions.
The Transportation Tradeoff Is Getting More Complex
Transportation has always involved tradeoffs. Shippers balance cost, service, speed, reliability, capacity, and customer expectations. Carbon adds another variable to an already complex decision environment.
A lower-emissions option may cost more, take longer, require consolidation, shift freight from truckload to intermodal, or require a different carrier. It may reduce flexibility or conflict with customer delivery expectations. This is why sustainability in transportation is difficult. Most companies support the concept until it creates operational compromise.
The TMS will increasingly become the place where those compromises are made visible. Instead of treating carbon as a number calculated after the shipment is complete, the system will need to show how emissions compare against cost, service, capacity, and customer commitments before the transportation decision is made.
Carbon Data Must Be Decision-Grade
For emissions to become a routing constraint, the data must be good enough to support operational decisions. High-level estimates may be acceptable for annual reporting, but they are often insufficient for execution-level planning.
Transportation teams need emissions data that is reasonably accurate by lane, mode, carrier, shipment profile, and equipment type. They also need consistent methodology. If the data is not trusted, planners will ignore it.
This creates a new requirement for TMS platforms: sustainability logic must be explainable. Users need to understand why one option is estimated to produce lower emissions than another. They also need to know whether the difference is material enough to influence the decision.
A system that simply displays a carbon number without context will have limited impact.
The Role of TMS in Sustainable Transportation
The TMS is naturally positioned to operationalize transportation sustainability because it already manages many of the relevant decisions. Mode selection, load consolidation, routing, carrier assignment, pool distribution, appointment planning, backhaul opportunities, empty miles reduction, expedite avoidance, and service-level tradeoffs all influence emissions performance.
Many of the best sustainability improvements in freight are also efficiency improvements. Better consolidation, fewer empty miles, improved routing, and reduced expedites can lower both cost and emissions. But not every sustainability decision pays for itself. Some will require explicit prioritization. That is where TMS configuration and governance become important.
A shipper may set different emissions rules by customer, product, region, business unit, or service level. For example, the system may recommend lower-emissions options when cost and service differences fall within an acceptable tolerance. It may flag high-emissions shipments for review, prioritize intermodal on certain lanes, or calculate the emissions impact of premium freight. This turns sustainability from a corporate aspiration into an operating policy.
The Coming Tension Between Cost, Service, and Carbon
The most interesting market development will not be the ability to calculate emissions. It will be the willingness to act on that information.
If the TMS recommends a lower-emissions route that costs the same and meets the same delivery window, the decision is easy. The harder cases are where sustainability creates tradeoffs. A lower-emissions option may cost more, add a day to transit, require greater planning discipline from the customer, reduce delivery flexibility, or improve corporate emissions performance while increasing local operating complexity.
These questions cannot be answered by software alone. They require policy decisions. The TMS can expose the tradeoff, recommend options, and enforce rules. But leadership must decide how much carbon matters relative to cost and service.
Why This Matters for Buyers
Shippers evaluating transportation technology should treat emissions capabilities as more than a reporting module. The important question is whether carbon can be used inside the planning and execution workflow.
A strong TMS should estimate emissions before shipment execution, compare cost, service, and carbon across routing options, support emissions rules by lane, customer, product, or mode, and help planners evaluate consolidation and mode-shift scenarios. It should also connect emissions performance to carrier scorecards and provide enough transparency for sustainability metrics to be audited and explained.
These capabilities distinguish basic carbon reporting from transportation sustainability management. The value is not simply knowing what emissions were last quarter. The value is understanding which operational changes can reduce emissions in the next planning cycle, the next procurement event, or the next shipment decision.
Sustainability Will Become Part of Transportation Optimization
Carbon will not replace cost or service as the dominant transportation decision factor. Freight still has to move reliably and economically. But carbon will increasingly become part of the optimization model.
That is the real shift.
Sustainability reporting looks backward. Transportation optimization looks forward. The market is moving from one to the other.
The winners will be shippers that use emissions data not merely to explain what happened, but to improve what happens next.
Carbon is becoming a routing constraint. The TMS will be where that constraint becomes operational.
Download the TMS Market Research Executive Summary for a strategic view of how carbon, routing, and transportation decision intelligence are becoming part of the modern TMS market.
The post Carbon Is Becoming a Routing Constraint, Not Just a Reporting Metric appeared first on Logistics Viewpoints.


How Supply Chain Technology Providers Can Build Market Visibility with Research, Webinars, Podcasts, and Thought Leadership

Supply Chain and Logistics News Weekly Round Up June 22nd-26th 2026
Carbon Is Becoming a Routing Constraint, Not Just a Reporting Metric

Why Sulfuric Acid Is Emerging as a Supply Chain Constraint in Copper

Walmart and the New Supply Chain Reality: AI, Automation, and Resilience
Container rates starting to spike on peak season rush – June 2, 2026 Update
Trending
-
 Non classé2 mois ago
Non classé2 mois agoWhy Sulfuric Acid Is Emerging as a Supply Chain Constraint in Copper
-
 Non classé1 an ago
Non classé1 an agoWalmart and the New Supply Chain Reality: AI, Automation, and Resilience
- Non classé4 semaines ago
Container rates starting to spike on peak season rush – June 2, 2026 Update
- Non classé11 mois ago
13 Books Logistics And Supply Chain Experts Need To Read
- Non classé8 mois ago
Ex-Asia ocean rates climb on GRIs, despite slowing demand – October 22, 2025 Update
- Non classé5 mois ago
Container Shipping Overcapacity & Rate Outlook 2026
-

 Non classé1 an ago
Non classé1 an agoAmazon and the Shift to AI-Driven Supply Chain Planning
- Non classé4 mois ago
Ocean rates ease as LNY begins; US port call fees again? – February 17, 2026 Update